

6·
2 months agoMy dynamic IP rarely changes. When it does, it gets updated by a Docker favonia/cloudflare-ddns image. I have yet to notice downtime.
My dynamic IP rarely changes. When it does, it gets updated by a Docker favonia/cloudflare-ddns image. I have yet to notice downtime.

This also means modifying your git pull command to pull the correct branch. A small change perhaps, but may be harder than just committing to main lol.
I had a similar problem with GitHub actions, it was hard to test without messing up the main repo history.
I would love to see alternatives/replacements to them that are less opinionated. If you aren’t ready to consign your entire library to destructive edits and file replacements then it really is hard to fit any arr program into your workflow. Because I have a few files I want to keep pristine and a few opinions on what gets downloaded, I’ve hit a snag every time I try to set up any arr program. Lidarr, for example, simply refuses to allow a root dir to be read only. I still have yet to get any up and running.
So no one else has to look it up, 120°F is 49°C

This is the closest local app I’ve found yet, thank you! The UI is different from what I am used to, but it has support for all tags in both the editor and the browser including support for adding custom tags. I thought dynamic playlists don’t exist and was technically right, because they are accomplished with saved searches. I realised that after checking docs. Thanks for the recommendation!
It’s the closest we’ve got, but it does not have multiple tag support that I can see. :( I am not surprised that it lacks multi-artist, that is niche, but even the genre only supports basic strings. So to create an auto playlist that only matches the “Rock” genre, you have to use contains which then matches Hard Rock, Alternative Rock, etc etc. I know I’m picky lol, but worth documenting this to save time for anyone else as picky as me.
Rhythmbox unfortunately does not support multiple tags, that I can see. It combines genres into one and any artist tag beyond the first is completely ignored and unsearchable.
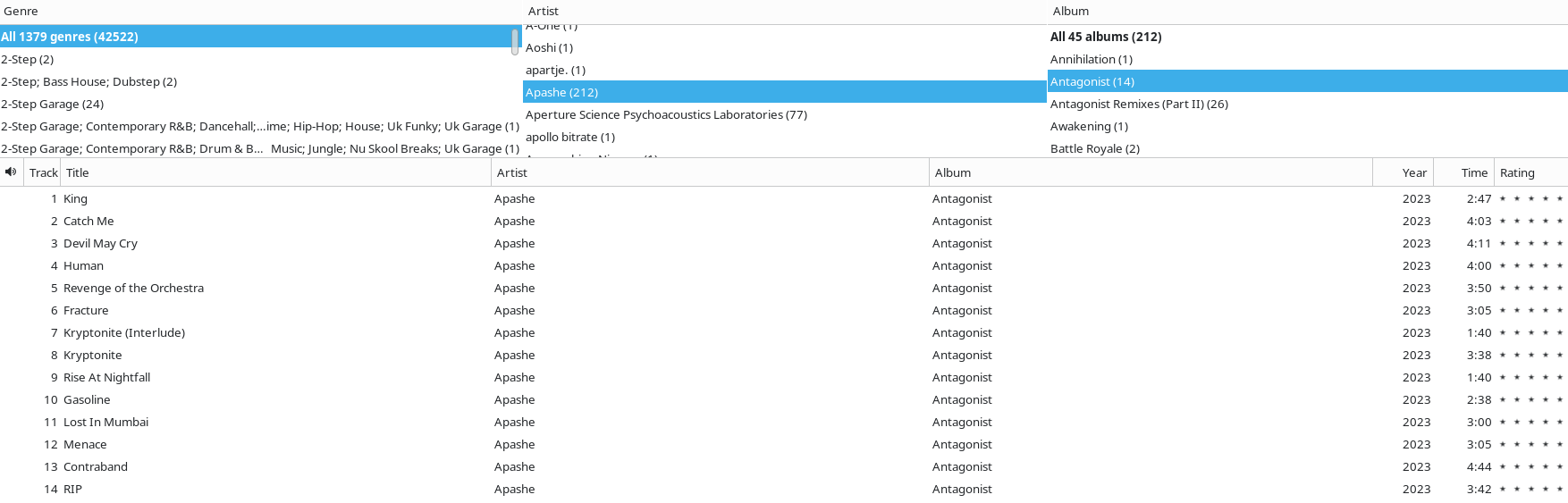
Amarok is a similar story, artists and genres are combined into one string. You can search them via “contains” but that is very imprecise.
Great recommendation on Feishin. Navidrome alone works for most of what I want as it does respect multiple artist tags, but the default web UI is subjectively bad and lacks any way to add smart playlists. Feishin solves both of those issues. I’ll be testing this further, it may just solve my browsing problems! I knew about Beets from a long time ago but never checked it out, I’ll have to see how that goes for my back-end needs. I have a feeling the disconnect between front-end and back-end will likely annoy me for a while as I try adding new files, but we’ll see.
I assume this is what you are trying to achieve by using a visual artist tag?
The display artist (a MusicBee-specific feature) is just an easy way to keep multiple artists in the artist tag while retaining a nice readable tag. For instance that artist tag would be Apashe; Wasiu but the display would be Apashe feat. Wasiu. MusicBrainz does something similar but uses artists instead of artist and artist instead of displayartist. Feishin displays the raw data nice enough I don’t mind losing the display though (it’s all in the tags anyway, no actual data loss there).
I’ve used it a lot on Windows! Quite handy for preliminary tagging. I haven’t used its file organisation though, but it could do the trick. I found the scripting language so obtuse though that I decided I’d rather tackle Python’s Mutagen library jank instead >_>
The quality has held despite a drop in users.
I feel like I’m going mental over here because this has not been my experience. The quality has always been spotty, but the last few months I’ve noticed more and more posts linking to awful “news” rags or no source at all. Worse, I rarely see people questioning the lack of quality information, simply gobbling it up because it aligns with their world view. Plus 70% of the comments on this platform could be generated by a classic r/subredditsimulator style bot and nothing would change; the same 5 points about AI, capitalism, and Linux are made in every thread in the exact same style every day.
And yes I’m mostly talking about news communities because Linux comms are usually fine but repetitive and while I’d love to interact with non-news content there just… isn’t much being made.
It doesn’t have to be, but by nature of anyone being able to spin one up, people will end up on hobby instances.
Traditional social media is run for-profit and thus has an incentive to keep their website online as much as possible to keep their company alive by gaining users and revenue. And I would bet they do have backups. Hobby websites like fediverse projects often are can be run by any flaky nobody that can have varying motives and varying data retention practices.

In this nazi analogy it would be less of buying chairs and more the nazis giving away chairs for free that come with blueprints so if the nazis started installing spikes in their chairs people can just build their own from the blueprints, they just choose not to because it’s a lot of work. Which is fine if you don’t want those chairs, but a lot of people are fine with those chairs as long as the nazis don’t start any camps.
Just skip to the point and make it 1 day
I believe that’s the joke, but I’m glad someone explained this for those that don’t know.
I have two identical HDDs as a mirror, another one that has no failsafe (but it’s fine, because the data it contains is non-critical)
On separate pools, I hope? My understanding of ZFS is that the loss of any vdev will mean the loss of the pool, so your striped vdev should be in its own pool that you don’t mind losing.
No no, ffmpeg is completely different! It refers to two women pegging a man.
I have been using TrueNAS Scale for a while but have not used base Linux for my NAS. My opinion is if you’re looking for a quick initial setup or are like me and didn’t want to install ZFS yourself, TrueNAS is rather appealing, but otherwise it doesn’t offer much. It has ZFS pre-installed, gives you a webUI to monitor basic things about your machine, and has fairly easy ways to setup data protection with snapshots and backups with rsync or zfs replication. In the more recent versions it even has Docker apps built-in so you can host some basic things. The downside of TrueNAS is that despite being Linux under the hood, it’s a lot more locked down so doing advanced measures is more of a pain and much of their “simpler” UI-based stuff is exceedingly basic, half-featured, and lacks documentation.
The way I use TrueNAS right now is to treat the main OS as mainly untouchable. I don’t try to break out of the limits placed upon it. I instead use a “Jailmaker” machine (defunct wrapper script for systemd-nspawn) for all my Docker needs. This way the main system remains more stable. If I have to re-install, then it’s a simple config import and my NAS is back to how it was.
I would use the built-in VM tools or the built-in Docker tools for this, but A. they weren’t implemented or weren’t working when I set this up, and B. I found their setup rather… annoying. For instance, I tried to set up some apps with their previous app system and it required configuration before working and yet nowhere did anyone explain how to configure it so I was wokring blind. No one makes guides for setting up an app in the TrueNAS UI, so the extra layer of obfuscation was just a hinderance to me. Compare that to setting it up directly in Docker, there are a million guides and great documentation for everything I get stuck on. Thus, despite being the “harder” way to set it up, it was easier due to the existence of information about it.
So, looking at it objectively, what parts of TrueNAS do I even use compared to base Linux? Not much. I use the WebUI to accomplish basic tasks such as creating or modifying datasets and permissions, snapshots, SMB shares, etcetera. All the basic things are there and I use the UI for them. But ever since that initial setup I spend most of my time in the CLI adjusting my scripts and Docker config files, creating directories inside the datasets, fine-tuning permissions… I could definitely have gone for a base Linux install as long as I knew what to install for ZFS support, some manner of WebUI, and so on. TrueNAS just did all that initial setup for me, and having a more locked-down OS forced me to use safer methods of installing programs via containers and keeping my install a lot more portable which I plan to continue no matter what OS I use.
This was probably not helpful, but that’s been my experience of TrueNAS for what it’s worth. Whatever you do, just remember: RAID is not a backup. It is protection against drive faults, but an error in the RAID system itself or the RAID pool’s data requires a separate copy of the data stored elsewhere to restore.
that statement has been used so universally sarcastically that no one believes you’re being serious when you say it now.
Framework also has used soldered RAM in the past. Getting their newest model to use modular RAM was quite the boast.